1,414213562373095048801688724209698078569671
87537694807317667973799073247846210703885038
75343276415727350138462309122970249248360558
50737212644121497099935831413 ...
Die Zahl wird Ihnen vermutlich bekannt vorkommen. Sie sieht so aus wie die Wurzel aus 2. Zumindest sind ihre Stellen bis zu der Stelle, wo sie abbricht, mit denen der Wurzel aus 2 identisch.
Vorstellbar wõre, dass die Zahlenfolge sich ab dieser Stelle zu wiederholen beginnt, wie es mit ganzen Zahlen darstellbare Br³che tun. Wie wõre es mit 100.000 / 70711? Die ersten f³nf Stellen nach dem Komma - 1,41421 - haben beide Zahlen tatsõchlich gemeinsam.
Sie brõuchten folglich, um die Wurzel aus 2 mit einem Bruch aus ganzen Zahlen darstellen zu k÷nnen, zwei unendlich lange Zahlen, was die mathematischen Definitionen verletzt ... weshalb man Zahlen wie diese in der Gruppe der irrationalen Zahlen zusammenfasst.
Unter diesen Irrationalzahlen gibt zwei Typen:
Die Algebraische Zahlen (etwa Wurzeln, z.B. , )
und
Die Transzendenten Zahlen (z. B. die Kreiszahl p = 3,14159... oder die Eulersche Zahl e = 2,71828...).
Irrationalzahlen durchlaufen im Gegensatz zu periodischen Zahlen das Zahlenspektrum scheinbar willk³rlich, man k÷nnte eine zufõllige Reihung vermuten - bzw. eine pseudozufõllige Reihung, denn welche Zahl auf die nõchste ist, mathematisch besehen, kein Zufall, sondern eine Notwendigkeit.
Die Schwierigkeit aber, aus den vorherigen Zahlen nur durchs blo▀e Ansehen die nõchste Zahl zu erraten, lõsst eine solche Zahl schnell merkw³rdig oder mysteri÷s erscheinen. Wiewohl sich, beim nõheren Hinsehen, auch deutliche Gesetzmõ▀igkeiten innerhalb ihrer Anordnung finden lassen.
Nehmen wir nur einmal die profane Zahlenhõufigkeit. Betrachten wir die ersten 10.000 Stellen der Goldenen Zahl Phi. Wie hõufig sind nun die jeweiligen Zahlen bei Phi verteilt?

Ziehen wir zum Vergleich eine Wurzel heran, die 2. Wurzel aus 10 . Sie zeigt noch geringere Abweichungen von dem Erwartungswert 1.000 bei 10.000 Nachkommastellen:
Wõhlen wir eine nicht-irrationale Zahl: Eine Zahl, die sich als Bruch darstellen lõsst wie zum Beispiel 1 / 1234567 . Bei den ersten 10.000 Stellen lõsst sich noch keine Periodizitõt nachweisen, es ist aber anzunehmen, dass sie eine periodische Struktur besitzt. Es ist erstaunlich: Auch sie zeigt noch sehr geringe Abweichungen von dem Erwartungswert 1.000, ist kaum von den irrationalen Zahlen zu unterscheiden:
Wõhlen wir unter den nicht-irrationalen Zahlen einen einfacheren Bruch:
1 / 1234 . Hier ist die Periodizitõt offensichtlich, die Zahlenfolge ...00810372771474878444084278768233387358184764
99189627228525121555915721231766612641815235...
mit insgesamt 88 Zahlen wiederholt sich 113mal bei den ersten 10.000 Stellen. Da innerhalb dieser Periode die Zahlen ungleich hõufig verteilt sind, wird hier der Erwartungswert von 1.000 oft deutlich ³ber- oder unterschritten. Hier w³rde gewiss niemand mehr von Zufõlligkeit sprechen wollen:
Wie man sieht, weist dieser Bruch zudem eine Symmetrie auf. Die Zahlen 4 und 5 sind gleichhõufig, ebenso 3 und 6, 2 und 7, 1 und 8 sowie 0 und 9.
Wie man sieht, verhelfen die Diagramme mit den Zahlenhõufigkeiten nur zu einer oberflõchlichen Einschõtzung der - ich nenne es hier einmal Zufallsstruktur einer Zahlenfolge. Man kann aus den Abweichungen beispielsweise die Varianz und die Standardabweichung ermitteln. In unserem Fall kõme man auf folgendes Abweichungs-Ranking bei den vier Zahlenfolgen (zuz³glich der Kreiszahl Pi als weiterer Vergleich):
Varianz / Standardabweichung
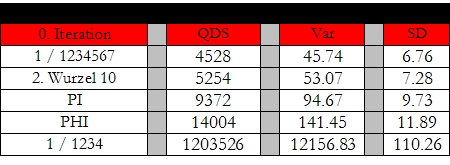
Die Begriffe QDS, VAR und SD werde ich im weiteren Verlauf noch en detail erklõren. Um es abzuk³rzen: Varianz und Standardabweichung definieren die durchschnittliche Abweichung der Erwartungswerte, also die Schwankungen um den Durchschnittswert.
Dieses Ergebnis ist verbl³ffend: Der Bruch 1/1234567 ist von geringerer Schwankung als Phi oder Pi, jene irrationalen Zahlen, die f³r ihre Irrationalitõt ber³hmt sind. Und selbst die Wurzel aus 10 hat geringere Ausrei▀er.
Was hei▀t das? Nur einmal angenommen, dieses Ergebnis bez÷ge sich nicht nur auf die ersten 10.000 Stellen, sondern 10.000x10.000 Stellen ... was w³rde das dann bedeuten? Dass 1/1234567 eine besonders zufõllige Zahl ist?
Nicht unbedingt! Denn es wõre auch ein Ergebnis mit einer Varianz von 0 denkbar! Eine, die 10x f³r jeden der zehn Zahlenwerte exakt 1.000x eine dieser Zahlen verwendet.
Denken Sie nur an die Zahlenfolge 012345678998765432100123456789987...
Wenn Sie diese Folge ins Unendliche fortschreiben, erhalten sie genau ein solches Ergebnis: Varianz und Standardabweichung 0!
Woraus man folgern k÷nnte: Eine Zahl, die eine sehr geringe bis gar nicht vorhandene Varianz/Standardabweichung aufweist, ist weniger zufõllig als eine Zahl wie die Goldene Zahl Phi oder Pi, die eine gewisse Streuung aufweisen, wenngleich die Streuung nicht zu deutlich und markant ausfõllt wie etwa beim Bruch 1/1234.
Dieses Ergebnis verbl³fft: Wom÷glich, k÷nnte man nun mutma▀en, liegt die wahrhaft irrationalste aller Zahlen irgendwo zwischen den sehr geringen und sehr hohen Varianz- und Standardabweichungswerten.
Eine geringe Varianz lõsst somit ein Schema vermuten, nach dem die nõchsten Werte sich an die vorangegangenen anf³gen, es gibt in einem solchen Fall also vermutlich ein System und kein pures Nichtsystem. Ebenso haben Reihen mit hoher Varianz meistens ein Schema - das Schema einer zu gro▀en Ordnung bzw. von Prõferenzen f³r bestimmte Zahlen.
Wõhrend also eine sehr geringe und eine hohe Varianz auf eine Ordnung schlie▀en lassen, m³ssten die Mittelwerte die zufõlligsten Zahlenfolgen aufweisen. Wenn also Pi und Phi in der Mitte dieser Skala hier stehen, k÷nnte man das damit erklõren, dass hier die chaotische Struktur von Zahlen von beiden Seiten durch geordnete Systeme umarmt, eingefasst wird.
Selbstverstõndlich ist das noch kein ³berzeugendes Kriterium. Wir nõhern uns damit erst dem Phõnomen von Ordungsstrukturen und Chaosstrukturen bei den Zahlenfolgen an.
Ich habe in einer ersten Analyse 20 zufõllig aussehende Zahlenfolgen (die meisten davon, sofern ich das beurteilen konnte, sind Irrationalzahlen) mit ihren ersten 1.000 Nachkommastellen nach dem obigen Schema der Varianz und der Standardabweichung untersucht. Ich habe aber auch noch weitere informative Aspekte mit in die Berechnung einbezogen. Woraus ich eine Formel entwickelt habe, die den Grad der Abweichung definiert:
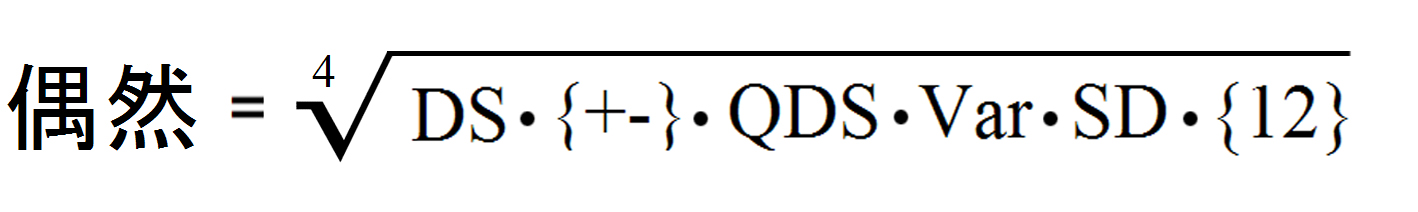
Was sich wie folgt aufschl³sselt:
| DS
|
Differenz-Summe (Abweichungen vom Mittelwert, summiert)
|
| {+-}
|
Abweichungen Zahlenwert 0/1 + 1/2 + 2/3 ... + 8/9 + 9/0
|
| QDS
|
Quadrate der Differenzen, summiert
|
| Var
|
Die Varianz. QDS/(n-1)
|
| SD
|
Die Standardabweichung. SD = Wurzel (var)
|
| {12}
|
Gr÷▀ere Summe/Kleinere Summe. {1} setzt sich zusammen aus den Zahlwerten 0-4, {2} aus den Zahlwerten 5-9
|
 ist das chinesische Schriftzeichen f³r Zufall bzw. "zufõllig"). hat sechs Komponenten oder Kriterien, von denen jedes einzelne den Grad von Zufõlligkeit bereits in Ma▀en beschreibt.
ist das chinesische Schriftzeichen f³r Zufall bzw. "zufõllig"). hat sechs Komponenten oder Kriterien, von denen jedes einzelne den Grad von Zufõlligkeit bereits in Ma▀en beschreibt.
Die Differenzsumme (DS) õhnelt hierbei der Quadratdifferenzsumme (QDS), und mit der Varianz (Var) erzeugt man sogar eine identische Reihenfolge wie mit der Standardabweichung (SD), wenn man eine Art Zufalls-Ranking aufstellen m÷chte. Die beiden eckig umklammerten Werte {+-} und {12} beschreiben die Nachbarschaften von den einzelnen Zahlwerten.
Bei {+-} wird eine Folge wie etwa diese Hõufigkeitsverteilung der Goldenen Zahl Phi (siehe oben):
0=1019
1=1062
2=994
3=1038
4=976
5=988
6=918
7=1025
8=987
9=991
bewertet nach dem Verlauf der Kurve (wie bei dem obigen Diagramm, welches lesbar wõre von links nach rechts oder umgekehrt). Erst vergleicht man die Werte 0 und 1, in diesem Fall ergibt 1062-1019 den Zahlwert "43". Dann vergleicht man 1 und 2 und bildet die Differenz. Aus den 10 Differenzen, die man erhõlt, ermittelt man die Betrõge und summiert sie - und erhõlt dann den Wert {+-}, der in die Berechnung von eingeht.
Mit {12} ermittelt man, ob es ein ausgewogenes Gleichgewicht aus den niedrigen Zahlbereich von 0-4 und dem hohen Zahlbereich von 5-9 gibt. (An diese Stelle wõre zu ³berlegen, ob man auch noch ein Wert f³r den Faktor Gerade-Ungerade ermittelt, also ein {GU}.)
Damit der Wert von nicht vielstellig wird, ermittelt man aus dem Produkt der sechs Formelkomponenten die vierte Wurzel. Es k÷nnte auch die sechste oder achte Wurzel sein - der Wert an sich spielt keine Rolle. Allein schon deshalb, weil er deutlich variiert, wenn man beispielsweise 10.000 Nachkommastellen betrachtet oder 1.000.000. ist somit nur dann als Zahlwert vergleichbar, wenn man die gleiche Zahlenmenge ber³cksichtigt hat.
Sie werden interessiert sein, was bei dem ersten Zufalls-Ranking herauskam. Sie k÷nnen es hier unter einsehen.
